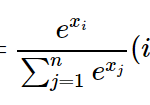こちらを読むと
- AIに関する職種って実際どうなのか?をフワッと知ることができます。
- SIerエンジニアが知識ゼロからAIを勉強した過程と所感を知ることができます。
結論:AI職は、エンジニアの上位職ではなく、別物
先に結論ですが、AIに関する職種は、一般的なエンジニアの上位職ではなく、全くの別物だと感じました。
ここでいうAI職は、機械学習エンジニア / データサイエンティストを指します。
著者について
私は現役の某SIer社員で、新入社員として入社し、10年以上Javaのシステム開発を担当しています。
最初は安定志向で今の会社に入ったのですが、数年前からやりたいこととのミスマッチを考え、今は独学で機械学習を学んだり、ブログを書いたり、いろいろ活動している最中です。
機械学習に興味を持ち、約1年間AI(機械学習、データサイエンス)の勉強をしてきました。実績はざっくり以下のような感じです。
- 書籍20冊ほどを独習(プログラムを写経して学習)
- 機械学習のスクールに4か月通った
- kaggleコンペは3件ほど参加(結果は未だ奮わず..)
AI職と一般エンジニアとの違い
ここからは、AI職(機械学習エンジニア、データサイエンティスト)と一般エンジニアとの違いについて、自分が思うところを解説していきます。
一般エンジニアは、ソフトウェアの仕様決め、設計、プログラミングが出来る前提とすると、その差分は以下のようになってくると思います。
機械学習エンジニアが一般エンジニアと違うところ

まずは、機械学習エンジニアと一般エンジニアの違いです。
- 機械学習のモデリングの知識が必要
- データ加工のスキルが必要
- 数学必須で、数式が読めないとだめ
- スキルアップするには論文を読む必要がある
順番に解説していきます。
機械学習のモデリングの知識が必要
機械学習エンジニアは、ビジネス課題によって、機械学習のどのモデルを使うのかを選択する必要があります。そのためには各モデルに精通している必要があります。
教師あり学習(分類/回帰)、教師なし学習、それぞれでモデルの種類も多数あり、自分の中に持っている選択肢を多くもっていないと、適切なモデリングができないと思います。
データ加工のスキルが必要
機械学習のインプットとなるデータは、学習できる形式にフォーマットされている必要がありますが、現場で得られる生データはその形式になっていないので、データを加工する必要があります。
この作業がかなり大変で、現場によっては業務の8割以上がデータ加工ということもあるようです。
Pythonを使うのであれば、そのライブラリであるnumpyやpandasを使ってデータを加工する技術が求められます。この点はエンジニアリングにかなり近いのではないでしょうか(特徴量エンジニアリングとも呼ばれる)。
数学必須で、数式が読めないとだめ
機械学習モデルを自前で作るためには、モデルを数式で表し、実装できる能力が必要です。
ライブラリを使う場合でも、仕組みを理解するためには数式理解が必要です。
数学の知識としては、大学1、2年くらいまでの線形代数、微分の知識が要求されるため、数学が全く苦手という人には向かないと思います。
スキルアップするには論文を読む必要がある
最新のモデルはライブラリ化されていないため、論文を読んで自分でモデリングする必要があります。個人的には、この部分のハードルが最も高く、トップクラスの機械学習エンジニアになるうえでの障壁になっていると思います。
いかがでしょうか。特に数学、論文の必要性については、かなり一般エンジニアと違いますよね。
データサイエンティストが一般エンジニアと違うところ

続いて、データサイエンティストと一般エンジニアの違いです。
- 機械学習のモデリングの知識が必要
- データ加工のスキルが必要
- 統計の知識を使って分析
- ビジネス課題の解決力
前半2点は変わらないかと思います。
残り2点について解説します。
統計の知識を使って分析
データサイエンティストは、統計の知識を使って分析することが一般的なようです。機械学習エンジニアでも知識はあった方が良いのですが、特にデータサイエンティストは持っている印象です。
統計の知識は幅広く、平均、分散、確率、検定など、多岐にわたります。
統計の知識を得るには、以下のサイトが有名です。
【統計WEB -統計学の時間-】
https://bellcurve.jp/statistics/course/
ビジネス課題の解決力
データサイエンティストと機械学習エンジニアと大きく違うところが、ビジネス課題の解決力が求められる部分だと個人的に思います。
データサイエンティストはコンサルティングの要素が大きく、顧客のビジネス課題を解決するためにデータ分析を行うイメージです。
いかがでしょうか。データサイエンティストは機械学習エンジニア以上に、一般エンジニアとかけ離れている印象です。
素人の憶測では?
ここまで書くと、「あなたは実際にAI職として働いてもいないのに、憶測に過ぎないのではないですか?」と言われるかもしれません。
実際にその通りだとは思いますが、完全に私個人の意見ではないです。同時期に勉強し始めた仲間も同じようなことを言っていますし、書籍やWeb情報を見る限り、外してはいないと思います。
また、私の意見はこちらの書籍も参考にしています。
こちらは、機械学習エンジニアとデータサイエンティストについて詳しく書かれていますので、良かったら読んでみてください。
まとめ
以上の通り、私の意見としては、AI職(機械学習エンジニア、データサイエンティスト)は、エンジニアの上位職ではなく、かなり別物だと思います。
私はJavaエンジニアとして働いていますが、機械学習に興味があり仕事にしたいので、機械学習エンジニア or データサイエンティストを目指すべく、勉強中です。
勉強した内容をブログやTwitterで発信していますので、良かったらフォローしてみてください。