
こちらを読むと
- scikit-learnのload_iris datasetについて、詳細が分かります。
何がしたいか
scikit-learnのload_iris dataset を使ってデータ分析の練習をしようと思ったのですが、そもそもどういうデータが入っているのか?データの型はどうなっているのか?など疑問点が出てきました。
データをまとめた決定版のようなものが見つからなかったので、書いてみることにしました。
load_iris dataset
公式ページはこちら
非常に簡単な多クラス分類用のデータセットです。
| 情報 | 値 |
|---|---|
| クラス数 | 3 |
| クラス毎のデータ数 | 50 |
| サンプル合計数 | 150 |
| 次元 | 4 |
| 特徴量 | 最小 | 最大 | 平均 | 標準偏差 |
|---|---|---|---|---|
| sepal(がく)の長さ [cm] | 4.3 | 7.9 | 5.84 | 0.83 |
| sepal(がく)の幅 [cm] | 2.0 | 4.4 | 3.05 | 0.43 |
| 花びらの長さ [cm] | 1.0 | 6.9 | 3.76 | 1.76 |
| 花びらの幅[cm] | 0.1 | 2.5 | 1.20 | 0.76 |
| クラス |
|---|
| Iris-Setosa |
| Iris-Versicolour |
| Iris-Virginica |
まとめ
- scikit-learnのload_iris datasetについて、詳細が分かりました。
これでload_irisの基本情報が押さえられたので、データ分析することができます!
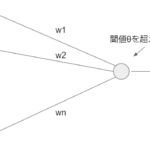
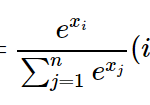


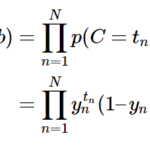





[…] 前回のブログで、load_irisのdatasetを解説しました。今回はこのデータを観察していきます。 […]