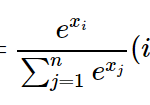こちらを読むと
- ロジスティック回帰の勾配法について、パラメータの更新式へ変換する方法を理解できます
前回の記事で、ロジスティック回帰の交差エントロピー誤差関数について、勾配法で最小化してパラメータを求める手法を説明しました。今回は勾配法の式をさらに変形して、実装に落とし込める形まで求めます。
勾配法の式のおさらい
交差エントロピー誤差関数は以下の式で表せます。
$$
\begin{eqnarray*}
E({\bf w}, b) &:=& -logL({\bf w}, b) \\
&=& – \sum_{n=1}^N \{t_n log y_n + (1 – t_n) log (1 – y_n)\}
\end{eqnarray*}
$$
~詳解ディープラーニングより抜粋~
そして、ロジスティック回帰の勾配法は以下の式で表せるのでした。
$$
{\bf w}^{(k+1)} = {\bf w}^{(k)} – \eta \frac{\partial E({\bf w},b)}{\partial {\bf w}} \\
b^{(k+1)} = b^{(k)} – \eta \frac{\partial E({\bf w},b)}{\partial b}
$$
~詳解ディープラーニングより抜粋~
この式を変形していきます。目標は、入力\( {\bf x}_n \)、出力\( y_n \)、実際の結果\( t_n \) を使って式を表すことです。それらは問題を解くときにデータが存在するはずなので、実装に落とし込めます。
勾配法の式変形
$$
E_n := – \{ t_nlogy_n + (1-t_n)log(1-y_n) \}
$$
とおくと、交差エントロピー誤差関数は
$$
E({\bf w}, b) = \sum_{n=1}^N E_n
$$
となります。したがって偏微分は以下のように変形できます。
$$
\begin{eqnarray*}
\frac{\partial E({\bf w},b)}{\partial {\bf w}} &=& \sum_{n=1}^N \frac{\partial E_n}{\partial {\bf w}} \\
ここで偏微分の連鎖律を使って、\\
&=& \sum_{n=1}^N \frac{\partial E_n}{\partial y_n} \frac{\partial y_n}{\partial {\bf w}} \\
&=& – \sum_{n=1}^N \frac{\partial \{ t_nlogy_n + (1-t_n)log(1-y_n) \}}{\partial y_n} \frac{\partial y_n}{\partial {\bf w}} \\
対数(log)の微分公式から、\\
&=& – \sum_{n=1}^N (\frac{t_n}{y_n} – \frac{1-t_n}{1-y_n}) \frac{\partial y_n}{\partial {\bf w}} (※1)\\
\end{eqnarray*}
$$
~詳解ディープラーニングより抜粋~
シグモイド関数の微分を用いて式変形
ここで、シグモイド関数の微分
$$
\sigma'(x) = \sigma(x)(1 – \sigma(x))
$$
を用いて、
$$
\begin{eqnarray*}
y_n &=& \sigma({\bf w}^T{\bf x_n} + b) \\
z_n &=& {\bf w}^T{\bf x_n} + b \\
\end{eqnarray*}
$$
とおくと、\( y_n = \sigma(z_n) \)となり、
$$
\begin{eqnarray*}
\frac{\partial y_n}{\partial {\bf w}} &=& \frac{\partial y_n}{\partial z_n} \frac{\partial z_n}{\partial {\bf w}} \\
&=& y_n(1-y_n) \frac{\partial z_n}{\partial {\bf w}} \\
\end{eqnarray*}
$$
そして、
$$
\begin{eqnarray*}
\frac{\partial z_n}{\partial {\bf w}} &=& \frac{\partial( {\bf w}^T{\bf x_n} + b )}{\partial {\bf w}} \\
ベクトルの微分公式から、\\
&=& {\bf x_n}
\end{eqnarray*}
$$
すなわち、以下のようになります。
$$
\frac{\partial y_n}{\partial {\bf w}} = y_n(1-y_n) {\bf x_n}
$$
~詳解ディープラーニングより抜粋~
パラメータの更新式
(※1)式に代入すると、
$$
\begin{eqnarray*}
\frac{\partial E({\bf w},b)}{\partial {\bf w}} &=& – \sum_{n=1}^N (\frac{t_n}{y_n} – \frac{1-t_n}{1-y_n}) y_n(1-y_n) {\bf x}_n \\
&=& – \sum_{n=1}^N \{t_n(1 – y_n) – y_n(1 – t_n)\}{\bf x}_n \\
&=& – \sum_{n=1}^N (t_n – y_n){\bf x}_n
\end{eqnarray*}
$$
バイアスbについても同様の変形を行い、
$$
\frac{\partial E({\bf w},b)}{\partial b} = – \sum_{n=1}^N (t_n – y_n)
$$
最終的に、パラメータの更新式は以下のようになります。
$$
\begin{eqnarray*}
{\bf w}^{(k+1)} &=& {\bf w}^{(k)} + \eta \sum_{n=1}^N(t_n – y_n){\bf x}_n \\
b^{(k+1)} &=& b^{(k)} + \eta \sum_{n=1}^N(t_n – y_n){\bf x}_n \\
\end{eqnarray*}
$$
~詳解ディープラーニングより抜粋~
まとめ
- ロジスティック回帰の勾配法について、パラメータの更新式へ変換する方法を理解できました
交差エントロピー誤差関数の式変形はなかなか大変ですが、いちどパラメータの更新式まで導出しておくと、理解が深まると思います。
Reference
詳解ディープラーニング
https://book.mynavi.jp/manatee/books/detail/id=72424