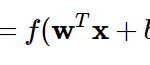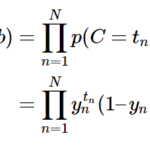要約
我々は、BERTと呼ばれる新しい言語表現モデルを導入した。これはBidirectional Encoder Representations from Transformersの略である。最近の言語表現モデル(Petersら、2018a; Radfordら、2018)とは異なり、BERTは、 すべての層において、左と右の両方の文脈に共同で条件付けを行うことで、ラベル付けされていないテキストから、深い双方向性の表現を事前学習するように設計されている。その結果、事前に学習された BERT モデルは、わずか 1 つの追加出力層でファイン・チューニング(微調整)することができ、質問回答や言語推論などの広範囲のタスクに対して、タスク特有のアーキテクチャを大幅に変更することなく、最先端(SOTA)のモデルを作成することができる。BERT は概念的にシンプルで経験的に強力である。GLUEスコアを80.5%(7.7ポイントの絶対的改善)、MultiNLI精度を86.7%(4.6ポイントの絶対的改善)、SQuAD v1.1質問応答テストF1を93.2(1.5ポイントの絶対的改善)、SQuAD v2.0テストF1を83.1(5.1ポイントの絶対的改善)に押し上げるなど、11の自然言語処理タスクで新たな最先端(SOTA)の結果を得ている。
1 序論
言語モデルの事前訓練は、多くの自然言語処理タスクの改善に有効であることが示されている(Dai and Le,2015; Peters et al.2018a; Radford et al.2018; Howard and Ruder,2018)。これらには、文を全体的に分析することによって文間の関係を予測することを目的とする自然言語推論(Bowman et al.,2015;Williams et al.,2018)や言い換え(Dlan and Brockett,2005)のような文レベルのタスクや、名前付き実体認識や質問回答のようなトークンレベルのタスクが含まれ、トークンレベルでのきめ細かな出力がモデルに求められる(Tjong Kim Sang and De Meulder,2003;Rajpurkar et al.,2016)。
事前学習した言語表現を下流のタスクに適用するには、2つの戦略がある。特徴ベースとファイン・チューニングである。ELMo(Peters et al., 2018a)のような特徴ベースのアプローチは、事前学習した表現を新たな特徴として追加する、タスク固有のアーキテクチャを使用する。Generative Pre-trained Transformer (OpenAI GPT) (Radford et al., 2018)のようなファイン・チューニングアプローチは、最小限のタスク固有のパラメータを導入し、事前学習したすべてのパラメータを単にファイン・チューニングすることによって、下流のタスクで学習される。この2つのアプローチは、事前学習中において同じ目的を持っている。その事前学習では、一般的な言語表現を学習するために一方向性言語モデルが使用される。
我々は、現在の技術、特にファイン・チューニングアプローチにおいて、事前学習された表現の力が制限されていることを論じている。主な制限は、標準的な言語モデルが一方向性を持っていることであり、このことが事前学習中に使用できるアーキテクチャの選択を制限している。例えば、OpenAI GPTでは、著者らは”左から右へ”のアーキテクチャを使用しており、すべてのトークンがトランスフォーマーのself-attention層で前のトークンにしかアテンションできない(Vaswani et al., 2017)。このような制限は文レベルのタスクには最適ではなく、質問応答のようなトークンレベルのタスクにファイン・チューニングベースのアプローチを適用する場合には非常に有害である可能性がある。よって双方向からのコンテキストを組み込むことが重要になってくる。
本論文では、ファイン・チューニングをベースとしたBERT: Bidirectional Encoder Representations from Transformers を提案することで、このアプローチを実現している。BERT は、Cloze タスク(Taylor, 1953)に触発された「マスクされた言語モデル」(MLM)の事前学習方針を使用することで、前述の単一方向性制約を緩和する。マスクされた言語モデルは、入力からトークンの一部をランダムにマスクし、その文脈のみに基づいてマスクされた単語の元の語彙IDを予測することが目的である。 “左から右へ” の言語モデル事前学習とは異なり、MLMの方針は左と右の文脈を融合させた表現を可能にすることで、深層双方向トランスフォーマーの事前訓練を可能にしている。また、マスクされた言語モデルに加えて、テキストペア表現を共同で事前学習する「次の文予測」タスクも利用している。本論文の貢献は以下の通りである。
我々は、言語表現のための双方向性事前学習の重要性を実証する。事前学習に一方向性言語モデルを使用するRadfordら(2018)とは異なり、BERTは事前学習された深い双方向性表現を可能にするためにマスクされた言語モデルを使用する。これは、独立して学習された”左から右へ”および”右から左へ”のLMの浅い連結を使用するPetersら(2018a)とも対照的である。
我々は、事前に学習された表現により、多くのしっかりと設計されたタスク固有のアーキテクチャの出番が減っていくと言っている。BERTは、文レベルおよびトークンレベルの大規模なタスクの組において最先端の性能を達成し、多くのタスク固有のアーキテクチャを凌駕する、初のファイン・チューニングベースの表現モデルである。
BERTは、11のNLPタスクのために最新の技術を進歩させている。コードと事前学習済みモデルは https://github.com/google-research/bert で入手可能である。
2 関連業務
事前学習された汎用的な言語表現の歴史は長い。このセクションでは最も広く使われているアプローチを簡単におさらいする。
2.1 教師なし特徴量ベースのアプローチ
広く適用可能な単語表現の学習は、非ニューラル(Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006)およびニューラル(Mikolov et al., 2013; Pennington et al., 2014)の手法を含め、数十年に渡って活発な研究が行われてきた。事前訓練された単語埋め込みは、現在のNLPシステムに不可欠なものであり、ゼロから学習された埋め込みと比べて大幅な改善を得ることができる(Turian et al., 2010)。単語埋め込みベクトルを事前学習するために、”左から右へ”の言語モデリングの方針が使用されてきた(Mnih and Hinton, 2009)。また、左の文脈と右の文脈を使い、正しい単語と正しくない単語を識別する方針が使用されてきた(Mikolov et al, 2013)。
これらのアプローチは、文の埋め込み(Kiros et al., 2015; Logeswaran and Lee, 2018)や段落の埋め込み(Le and Mikolov, 2014)のような粗い粒度に向けて般化されてきた。文表現を学習するために、先行研究では、候補となる次の文をランク付けするための方針(Jernite et al, 2017; Logeswaran and Lee, 2018)や、前の文の表現を与えられた上で次の文の単語を”左から右へ”生成する方針(Kiros et al, 2015)や、ノイズを除去するオートエンコーダー由来の方針(Hill et al, 2016)が使用されてきた。
ELMoとその前身(Peters et al., 2017,2018a)は、従来の単語埋め込みの研究を、異なる次元に沿って一般化したものである。それらは、”左から右へ”、”右から左へ”の言語モデルから、文脈の微妙な差を検知可能な特徴を抽出する。各トークンの文脈的表現は、”左から右へ”の表現と”右から左へ”の表現を連結したものである。ELMoは、文脈的な単語埋め込みを、既存のタスク固有アーキテクチャと統合することで、質問回答(Rajpurkarら、2016)、感情分析(Socherら、2013)、および固有表現の認識(Tjong Kim Sang and De Meulder、2003)を含むいくつかの主要なNLPベンチマーク(Petersら、2018a)について、最先端(SOTA)を走っている。Melamudら(2016)は、LSTMを用いて左右両方の文脈から単一の単語を予測するタスクを通じて文脈表現を学習することを提案した。ELMoと同様に、彼らのモデルは特徴ベースであり、深い双方向性はない。Fedusら(2018)は、テキスト生成モデルのロバスト性を向上させるためにclozeタスクを使用できると示している。
2.2 教師なしファイン・チューニングアプローチ
特徴ベースのアプローチと同様に、この方向の最初の研究では、ラベル付けされていないテキストから単語の埋め込みパラメータを事前に学習しただけである(Collobert and Weston, 2008)。
さらに最近では、文脈トークン表現を生成する文または文書エンコーダーが、ラベル付けされていないテキストから事前に学習され、次に待ちかまえている教師付きタスクのためにファイン・チューニングされている(Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018)。これらのアプローチの利点は、ゼロから学習する必要のあるパラメータが少ないことである。少なくとも一部はこの恩恵を受けて、OpenAI GPT(Radford et al., 2018)は以前に、GLUEベンチマーク(Wanget al., 2018a)の多くの文レベルタスクで最先端(SOTA)の結果を達成した。”左から右へ”の言語モデリングと自動エンコーダーの方針は、このようなモデルの事前訓練に使用されてきた(Howard and Ruder,2018; Radford et al.2018; Dai and Le,2015)。
2.3 教師ありデータからの転移学習
また、自然言語推論(Conneau et al., 2017)や機械翻訳(McCann et al., 2017)など、大規模なデータセットを用いた教師付きタスクからの効果的な転移を示す研究もある。また、コンピュータビジョンの研究では、大規模な事前学習モデルからの転移学習の重要性が実証されている。そこでは、ImageNetで事前学習されたモデルをファイン・チューニングすることが効果的とされている(Deng et al., 2009; Yosinski et al., 2014)。
3 BERT
このセクションでは、BERT とその詳細な実装を紹介する。我々のフレームワークには2つのステップがある:事前学習とファイン・チューニングである。事前学習中は、モデルは異なる事前学習タスクを通して、ラベル付けされていないデータで学習される。ファイン・チューニングでは最初に、BERT モデルは事前学習されたパラメータで初期化され、すべてのパラメータは下流タスクからのラベル付きデータを使用してファイン・チューニングされる。各下流のタスクは、同じ「事前学習されたパラメータ」で初期化されているにもかかわらず、個別にファイン・チューニングされたモデルを持っている。図1の質問応答の例は、このセクションの実行例である。
BERT の代表的な特徴は、異なるタスクにまたがる統一されたアーキテクチャである。事前に学習されたアーキテクチャ と最終的な下流の
アーキテクチャは、ほぼ変わらない。BERTのモデルアーキテクチャは、Vaswaniら(2017)に記載され、tensor2tensorライブラリで公開されているオリジナルの実装をベースにした多層双方向トランスエンコーダである。トランスフォーマーの使用が一般的になり、我々の実装はオリジナルとほぼ同じであるため、モデルアーキテクチャの網羅的な背景の説明は省略する。Vaswaniら(2017)や “The Annotated Transformer “などの優れたガイドを参照していただきたい。
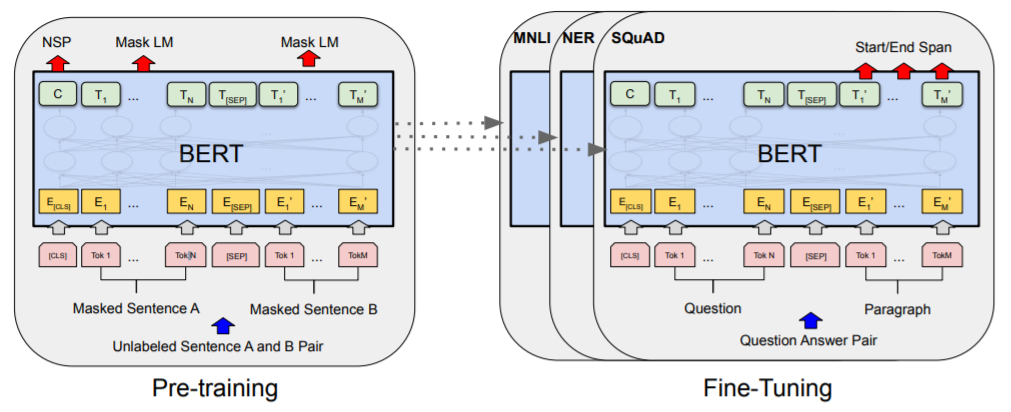
出力層とは別に、事前学習とファイン・チューニングの
両方で同じアーキテクチャが使用される。
異なるダウンストリームタスクのためのモデルの初期化には、
同じ事前学習モデルのパラメータが使用される。
ファイン・チューニングの段階では、すべてのパラメータがファイン・チューニングされる。
[CLS]はすべての入力例の前に追加される特別な記号であり、
[SEP]は特別なセパレータトークンである(例:質問と回答の分離)。
モデル・アーキテクチャ
BERTのモデルアーキテクチャは、Vaswaniら(2017)に記載され、tensor2tensorライブラリで公開されているオリジナルの実装をベースにした多層双方向トランスフォーマーのエンコーダである。トランスフォーマーの使用が一般的になり、我々の実装はオリジナルとほぼ同じであるため、モデルアーキテクチャの網羅的な背景説明を省略する。読者はVaswaniら(2017)や “The Annotated Transformer “のような優れたガイドを参照されたし。
本研究では、層の数をL、隠れサイズをH、self-attentionヘッドの数をAと表記する。主に2つのモデルサイズについての結果を報告する。BERTBASE (L=12, H=768, A=12, Total Parameters=110M)とBERTLARGE (L=24, H=1024, A=16, Total Parameters=340M)である。BERTBASEは、比較のためにOpenAI GPTと同じモデルサイズを持つように選択した。しかし、重要なことは、BERTトランスフォーマーは双方向のself-attentionを使用しているのに対し、GPTトランスフォーマーは、すべてのトークンがその左のコンテキストにのみ注意を払うことができる制約付きself-attentionを使用していることである。
入出力表現
BERT がさまざまなダウンストリーム作業を処理できることにより、入力表現は、1 つのトークン列で単一文と文の組(例:質問、回答)の両方を明確に表すことができる。この作業を通して、「文」は、実際の言語的文ではなく、連続したテキストの任意の長さとすることができる。「シーケンス」とは、BERT への入力トークンシーケンスを指し、これは単一の文である場合もあれば、2 つの文をまとめたものである場合もある。
我々は3万トークンの語彙を持つ単語埋め込み (Wu et al., 2016)を使用する。全シーケンスの最初のトークンは必ず、特殊な分類用トークン([CLS])である。このトークンに対応する最後の隠れ状態が、分類タスクのための集約シーケンス表現として使用される。シーケンスのペアを一つにまとめ、そのシーケンスを2つの方法で区別する。まず,特別なトークン([SEP])を用いてシーケンスを分離する.次に、図1に示すように、トークンが文Aに属するか文Bに属するかを示す学習済みの埋め込みを各トークンに付加する。ここでは、入力埋め込みをE、特殊[CLS]トークンの最終的な隠れベクトルをC ∈R Hと表記する。さらに、i 番目の入力トークンの最後の隠れベクトルを Ti ∈ R H とする。出力では、シーケンスタグ付けや質問応答などのトークンレベルのタスク用の出力レイヤに、トークン表現が入力され、含意や感情分析などの分類のための出力レイヤに、[CLS]表現が入力される。
与えられたトークンの入力表現は、対応するトークン、セグメント、および位置の埋め込みを合計することで構築される。この構造を図2に示す。
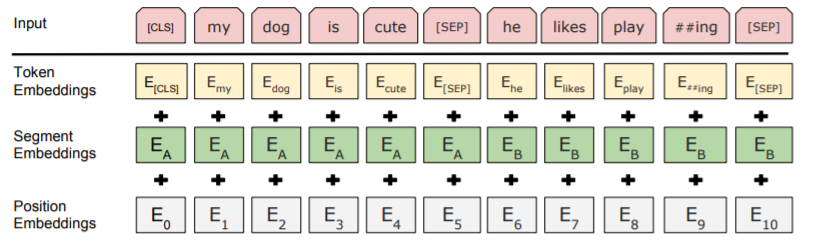
入力埋め込みは、トークン埋め込み、セグメンテーション埋め込み、
および位置埋め込みの合計である。
3.1 事前学習済みBERT
Petersら(2018a)およびRadfordら(2018)とは異なり、我々はBERTを事前学習するために伝統的な”左から右へ”または”右から左へ”の言語モデルを使用しない。その代わりに、本節で説明する 2 つの教師なしタスクを使用して BERT を事前学習する。このステップを図 1 の左部に表す。
タスク #1 Masked LM
直感的には、”左から右へ”のモデルや、”左から右へ”のモデルと”右から左へ”のモデルの浅い結合よりも、深い双方向性のモデルの方が厳密には強力と考えるのが妥当である。残念ながら、標準的な条件付き言語モデルは”左から右へ”か”右から左へ”にしか学習できない。なぜなら、双方向性条件付けは各単語が間接的に「自分自身を見る」ことを可能にし、モデルは多層的な文脈の中で対象の単語を簡単に予測できるからである。
深層双方向表現を学習するには、入力トークンの何%かをランダムにマスクし、そのマスクされたトークンを予測するだけである。この手法は、文献ではClozeタスクと呼ばれることが多いが(Taylor, 1953)、我々はこの手法を “masked LM” (MLM)と呼ぶ。この場合,標準的な言語モデルと同様に,マスクトークンに対応する最後の隠れベクトルは,語彙に対する出力のsoftmax に渡される。我々の実験では、各シーケンスに含まれる全ての単語のトークンの15%をランダムにマスクしている。オートエンコーダー (Vincent et al., 2008)のノイズ除去とは対照的に、入力全体を再構築するのではなく、マスクされた単語を予測するだけでよい。
これにより双方向の事前学習モデルを得られるが、事前学習とファイン・チューニングの間にミスマッチが生じる問題がある。これを軽減するために、必ずしも「マスクされた」単語を実際の[MASK]トークンに置き換えるわけではない。
学習データ生成器は、予測のためにトークン位置の15%をランダムに選択する。そして、i番目のトークンが選択された場合には、i番目のトークンを、(1)80%の確率で[MASK]トークンに(2)10%の確率でランダムなトークンに(3)10%の確率で変更されていないi番目のトークンに、置き換える。そして、Tiは、クロスエントロピー損失を有する元のトークンを予測するために使用される。この手順のバリエーションを付録C.2で比較する。
タスク #2 次の文の予測 (NSP)
質問応答(QA)や自然言語推論(NLI)のような下流の重要なタスクの多くは、言語モデリングでは直接捉えることのできない2つの文の関係性を理解することに基づいている。文の関係性を理解するモデルを学習するために、我々は二値化された次文予測タスクに対する事前学習を行う。そのタスクは、どのような単言語コーパスからでも簡単に生成できる。具体的には、それぞれの事前学習の例に対して、文AとBを選択する際に、50%はBが実際にAに続く文(IsNextと表示)とし、50%はコーパスからのランダムな文(NotNextと表示)とする。図1に示すように、Cは次文予測(NSP)に用いられる。そのシンプルさにもかかわらず、このタスクに対する事前学習がQAとNLIの両方に非常に有益であることを5.1節で実証している。
NSPタスクは、Jerniteら(2017)やLogeswaran and Lee(2018)で使用されている表現学習の目的と密接に関連している。ただし、先行研究では、文の埋め込みだけがダウンストリームタスクに転送されるが、BERTは最終タスクのモデルのパラメータを初期化するために全パラメータを転送する。
事前学習データ
事前学習の手順は、言語モデルの事前学習に関する既存の文献に概ね従っている。事前学習のコーパスには、BooksCorpus (800M words) (Zhu et al., 2015)と英語版Wikipedia (2,500M words)を使用する。ウィキペディアについては、テキスト部分のみを抽出し、リスト、表、ヘッダーは無視している。長い連続したシーケンスを抽出するためには、Billion Word Benchmark (Chelba et al., 2013)のようなシャッフルされた”文レベル”のコーパスではなく、”文書レベル”のコーパスを使用することが重要である。
3.2 ファイン・チューニングBERT
ファイン・チューニングは簡単である。なぜなら、トランスフォーマーのself-attentionメカニズムにより、BERT は、適切な入力と出力を入れ替えることで、単一のテキストまたはテキストの組を含む下流タスクの多くをモデル化することができるためである。テキスト組を含む応用では、一般的なパターンは、Parikh ら(2016);Seo ら(2017)のように、双方向のcross-attention適用前に、テキスト組を独立してエンコードする。BERT は、代わりにself-attentionメカニズムを用いて、これら 2 つの段階を統一する。self-attentionを用いて連結されたテキストペアをエンコードすることにより、2 つの文の間の双方向のcross-attentionを効果的に含めるためである。
各タスクについて、我々はタスク固有の入力と出力を BERT に代入し、すべてのパラメータをエンドツーエンドでファイン・チューニングするだけである。入力では、事前学習からの文 A と文 B は、(1) 言い換えにおける文の組、(2) 含意における仮説と仮定の組、(3) 質問応答における質問と文節の組、(4) テキスト分類またはシーケンスタグ付けにおける退化したテキストの組に類似している。
事前学習に比べて、ファイン・チューニングは比較的コストがかからない。本論文で紹介した結果はすべて、まったく同じ事前学習モデルから出発して、1台のクラウドTPUで最大1時間、GPUで数時間で再現可能である。タスク固有の詳細については、対応するセクション4のサブセクションで説明する。詳細は付録A.5に記載されている。
4 実験
本セクションでは、11のNLPタスクでのBERTのファイン・チューニング結果を紹介する。
4.1 GLUE
一般言語理解評価(GLUE)ベンチマーク(Wang et al., 2018a)は、多様な自然言語理解タスクの集合体である。GLUEデータセットの詳細な説明は、付録B.1に含まれている。
GLUE上でファイン・チューニングするには、セクション3で説明したように入力シーケンス(単文または文の組)を表現し、最初の入力トークン[CLS]に対応する最終的な隠れベクトルC∈R Hを、集約表現として使用する。ファイン・チューニングの間に導入される唯一の新しいパラメータは、分類レイヤの重みW ∈R K×Hである。ここでKはラベルの数である。CとWを用いて標準的な分類損失、すなわちlog(softmax(CWT))を計算する。
我々は32のバッチサイズを使用し、すべてのGLUEタスクについて、データ上で3エポック分のファイン・チューニングを行った。
各タスクについては、Devセット上で最適なファイン・チューニング学習率(5e-5, 4e-5, 3e-5, 2e-5の中から)を選択した。さらに、BERTLARGEについては、小さなデータセットではファイン・チューニングが不安定な場合があることがわかった。そのため、数回ランダムに再起動させ、Devセット上で最良のモデルを選択した。ランダムな再起動では、同じ事前学習済みチェックポイントを使用する。ただし、データシャッフリングと分類器層の初期化の、異なるファイン・チューニングを行っている。
結果を表 1 に示す。BERTBASEとBERTLARGEの両方が、すべてのタスクにおいてすべてのシステムを大幅に上回り、平均精度が先行技術と比較してそれぞれ4.5%と7.0%向上している。BERTBASEとOpenAI GPTは、注目マスキングを除けば、モデルアーキテクチャの点でほぼ同じであることに注意してもらいたい。最大かつ最も広く報告されているGLUE課題であるMNLIでは、BERTにより絶対精度が4.6%向上した。GLUEの公式順位表10では、OpenAI GPTは72.8点であるのに対し、BERTLARGEは80.5点となっている。
すべてのタスク、特に、訓練データが非常に少ないタスクにおいて、BERTLARGEがBERTBASEよりもかなり優れていることが分かった。モデルサイズの効果は、セクション5.2でより詳細に調査されている。
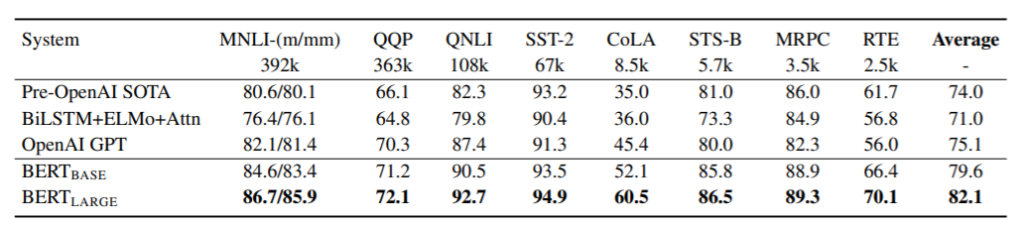
評価サーバ(https://gluebenchmark.com/leaderboard)によって採点されたもの。
各タスクの下の数字は学習例の数を示す。
問題のあるWNLIセットを除外しているため、
「平均」の欄は公式のGLUEスコアとは若干異なる。
BERTとOpenAI GPTはシングルモデル、シングルタスクである。
QQPとMRPCについてはF1スコアが、STS-Bについてはスピアマン相関が、
その他のタスクについては精度スコアが報告されている。
BERT を構成要素の 1 つとして使用している項目は除外している。
4.2 SQuAD v1.1
Stanford Question Answering Dataset (SQuAD v1.1)は、100k個のクラウドソースによる質問/回答組のコレクションである(Rajpurkar et al.,2016)。問題と、その答えを含むWikipediaの一節を与えられた場合、課題はその一節の答えのテキスト間隔を予測することである。
図1に示すように、質問応答タスクでは、入力された質問および一節を、質問は埋め込みA、一節は埋め込みBを用いて、一つのパックされたシーケンスとして表現している。ファイン・チューニングの際には、開始ベクトルS∈R Hと終了ベクトルE∈R Hのみを取り込む。単語iが解答の開始点である確率は、TiとSの間のドット積として計算され、その後、段落内のすべての単語に対してソフトマックスが与えられる。
解答の終了点についても同様の式を用いる。位置 i から位置 j までの候補スパンのスコアは S-Ti + E-Tj と定義され、j ≥ i の最大スコアリング・スパンが予測値として使用される。学習目的関数は、正しい開始位置と終了位置の対数尤度の合計である。学習率は5e-5、バッチサイズは32で、3エポックでファイン・チューニングを行う。
表2に、上位順位表のエントリと、公開システムの上位の結果を示す(Seo et al.,2017; Clark and Gardner,2018; Peters et al.,2018a; Hu et al.,2018)。QuAD順位表の上位結果は、最新の公開システムの内容が反映されていない。またシステムを学習する際には、任意の公開データを使用することが許可されている。しそのため我々のシステムにおいては、SQuADでのファイン・チューニングに先立ち、最初にTriviaQA (Joshi et al., 2017)でファイン・チューニングを行うことで、データを若干増強している。
我々の最高のパフォーマンスを発揮するシステムは、アンサンブルでは+1.5 F1、単一システムでは+1.3 F1で、順位表の上位システムを上回っている。実際、我々の単一BERTモデルは、F1スコアで上位のアンサンブルシステムを上回っている。TriviaQAのファイン・チューニングデータがなければ、0.1~0.4のF1スコアを失うのみで、それでも既存のすべてのシステムを大差で上回っている。
4.3 SQuAD v2.0
以下、作成中。。。
6 結論
言語モデルを用いた伝達学習による最近の実験的改善により、豊かで教師なしの事前学習が多くの言語理解システムの不可欠な部分であることが実証された。特に、これらの結果は、低リソースのタスクさえも深い一方向性アーキテクチャの恩恵を受けることを可能にしている。我々の主要な貢献により、これらの知見をさらに深い双方向性アーキテクチャに一般化し、同じ事前学習を受けたモデルが幅広いNLPタスクのセットに成功することができた。
www.DeepL.com/Translator(無料版)で翻訳した上、一部を手作業で直しました。